Abstract
Fingerprint recognition is one of the most popular biometric recognition methods nowadays. It is applicable in many areas in- cluding time recorder systems, criminal tracking, authentication and system security. However, one of the challenges to current traditional methods is the dependence on the minutiae extraction and recognition time. Hence, the limitations of these methods are that they do not effect to recognition in a large data environment. In addition, the processing of input image is very important for improving the accuracy of the recognition process. MapReduce technique is used in exploring and analyzing of large data that can not be processed on classical techniques due to some constraints on computer resources such as processing capability, memory, etc. We performed parallel processing in feature extraction and recognition with the MapReduce model in a Spark environment. we have also compared the accuracy and the runtime of our method before and after using MapReduce in the Spark. The experimental results show that the proposed method has achieved the automatic and effective fingerprint recognition.
Introduction
Fingerprint recognition is a widely used biometric identification method due to its uniqueness and stability over time. Fingerprints are easily collected and stored, making them a popular choice for security access control in various systems, such as cell phones, ATMs, and automobiles. To efficiently process and analyze large amounts of fingerprint data, the MapReduce technique is widely employed. This paper introduces the use of Gabor wavelet transformation and the MapReduce technique in a Spark environment for fingerprint identification. The proposed model utilizes MapReduce to handle large-scale fingerprint data, and the experimental results are presented using the FVC database
We have used the fingerprint database of FVC2000, FVC2002, FVC2004. Each database includes 320 fingerprint images of 40 persons totaling 960 fingerprints (total capacity is approximately 130MB)

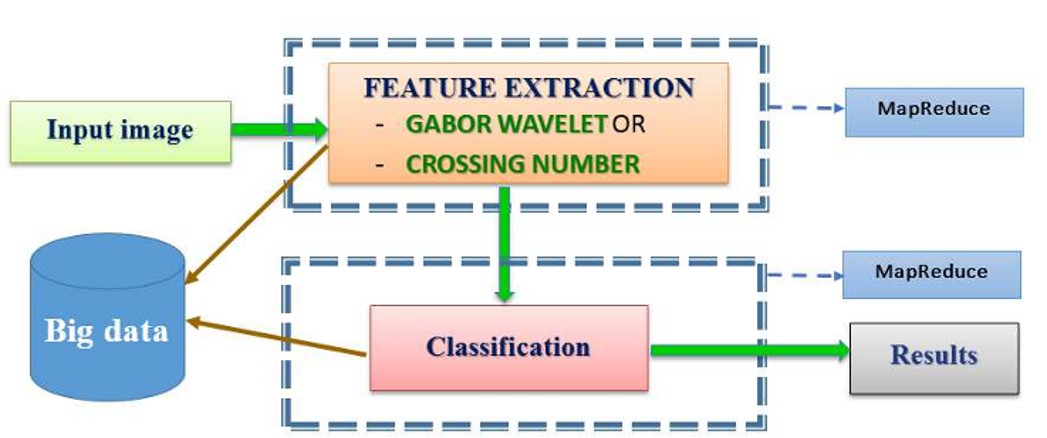
Proposed Method
the authors propose using a MapReduce model in a Spark environment to parallelize the key steps of feature extraction and classification, improving the runtime performance of the fingerprint recognition system
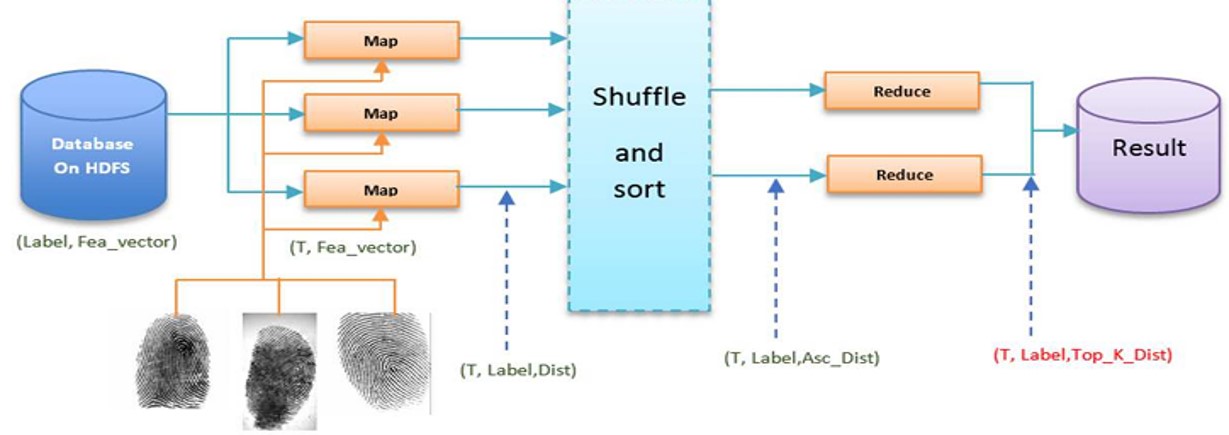
The testing phase of the proposed algorithm involves two approaches: K-Nearest Neighbors (KNN) and matching based on minutiae. The KNN approach calculates the distance between the testing and training data, stores the distance values with their corresponding class labels, and then determines the class with the highest count among the k nearest neighbors. The minutiae-based matching calculates a similarity score between the testing and training data, selects the maximum score, and assigns the corresponding class label. Both approaches leverage the MapReduce model in a Spark environment to parallelize the computations and improve the efficiency of the fingerprint recognition system.
Results
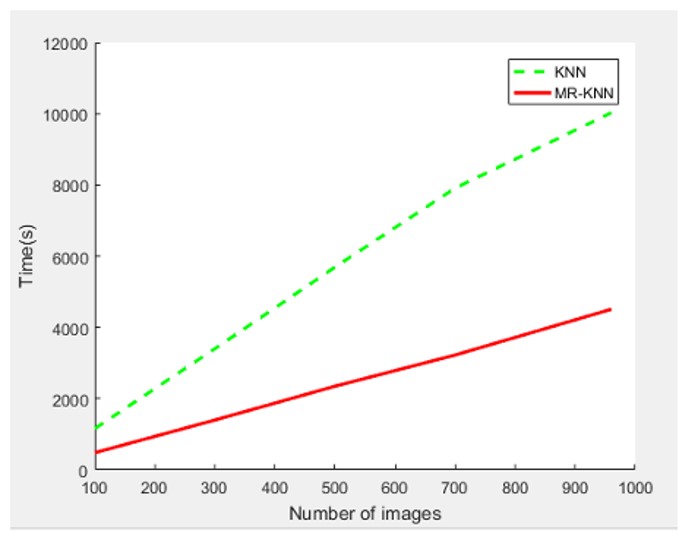
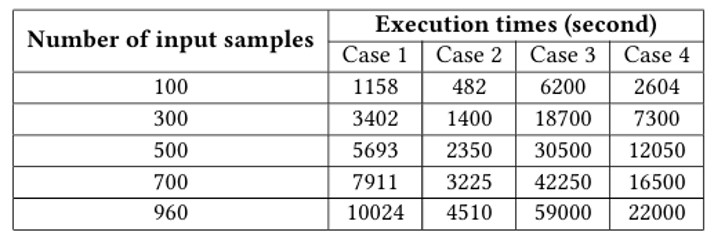
Case 1: Gabor + PCA + KNN.
Case 2: Gabor +PCA+KNN(usingMapReducemodelinSpark).
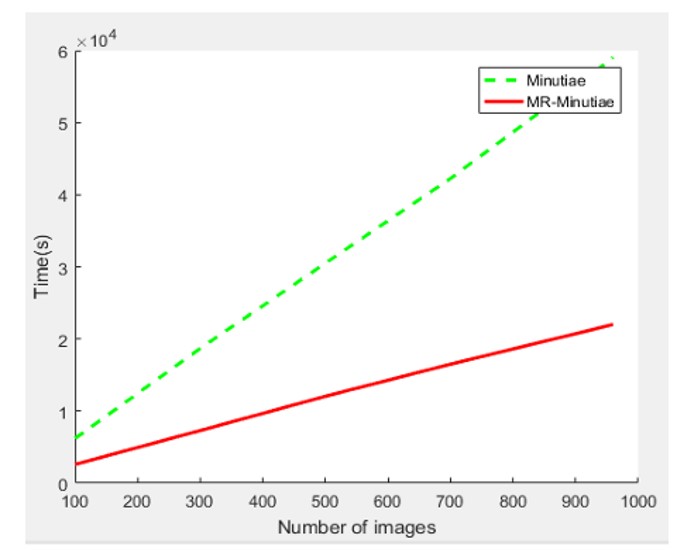
Case 3: Gabor + Crossing Number + Matching
Case 4: Gabor + Crossing Number + Matching (using MapRe duce model in Spark).
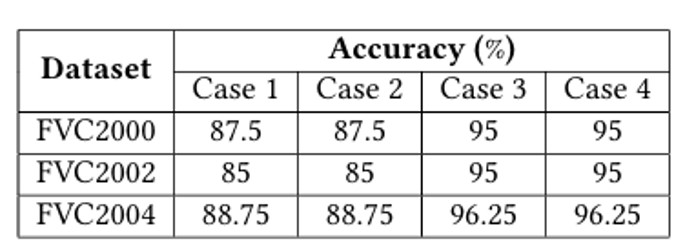
The results show that the fingerprint recognition accuracy is higher when the algorithm considers the minutiae points around the central region, as in cases 3 and 4, compared to cases 1 and 2. Furthermore, the application of the MapReduce model in a Spark environment significantly reduces the execution time of the recognition process, as evidenced by the comparison between cases 1 and 2, as well as cases 3 and 4. The parallel processing capabilities of the MapReduce model with Spark improve the efficiency of the fingerprint recognition system, especially when dealing with large datasets.
Conclusions
In this paper, the contributions are that the implementation of fingerprint recognition using MapReduce model in a Spark envi- ronment. It supports in-memory computing, which lets it query data faster than disk-based engines like Hadoop. The input image quality enhancement with Gabor filter gives very good results on fingerprints with low quality. Therefore, important features are preserved for the extraction. At the time of comparing four algo- rithms on two different sets of features (features of Gabor function and Crossing Number algorithm), the recognition results on Gabor filter's values are not as high as the method of point extract on the basis of Crossing Number algorithm. In addition, the execution time of the proposed system decreases the linearity when the number of nodes increases. The fingerprint recognition system based on MapReduce model satisfies the basic performance requirements. The experimental results also show that the accuracy is similar while the execution time decreases significantly compared to the traditional methods due to the use of parallel computing methods and direct data processing on the internal memory. For future work, we will work on larger data sets with the number of large system nodes that can perform real-time recognition.
References
- JC Amengual, A Juan, JC Pérez, F Prat, S Sáez, and JM Vilar. 1997. Real-time minutiae extraction in fingerprint images. (1997)
- Prajesh P Anchalia a nd Kaushik Roy. 2014. The k-nearest neighbor algorithm using MapReduce paradigm. In Intelligent Systems, Modelling and Simulation (ISMS), 2014 5th International Conference on. IEEE, 513–518.
- Monowar H Bhuyan, Sarat Saharia, and Dhruba Kr Bhattacharyya. 2012. An effective method for fingerprint classification. arXiv preprint arXiv:1211.4658 (2012).
- Thomas Cover and Peter Hart. 1967. Nearest neighbor pattern classification. IEEE transactions on information theory 13, 1 (1967), 21–27.
- Ian T Jolliffe. 1986. Choosing a subset of principal components or variables. In Principal Component Analysis. Springer, 92–114.
- HoldenKarau, AndyKonwinski,Patrick Wendell, and Matei Zaharia. 2015. Learning spark: lightning-fast big data analysis. " O’Reilly Media, Inc.".
- HoldenKarau, AndyKonwinski,Patrick Wendell, and Matei Zaharia. 2015. Learning spark: lightning-fast big data analysis. " O’Reilly Media, Inc.".
- INHO KIM1, Byung-Soo Kim, and Silvio Savarese. 2012. Comparing image classification methods: K-nearest-neighbor and support-vector-machines. Ann Arbor 1001 (2012), 48109–2122.
- Lu Liu. 2015. Performance comparison by running benchmarks on Hadoop, Spark, and HAMR. Ph.D. Dissertation. University of Delaware.
- Jesús Maillo, Isaac Triguero, and Francisco Herrera. 2015. A mapreduce-based k nearest neighbor approachfor bigdataclassification. In Trustcom/BigDataSE/ISPA, 2015 IEEE, Vol. 2. IEEE, 167–172.
- Lindsay I Smith. 2002. A tutorial on principal components analysis. Technical Report.