Abstract
Research deep learning models such as VGG16, and based on that, explore how to implement and train these models in a big data environment using distributed processing tools like Spark and Hadoop. Deploy a pilot model on a Hadoop/Spark cluster. Install and configure the components of the system for training and recognizing diseases on tomato and potato leaves in a big data processing environment. According to the experimental results, a dataset of leaf diseases was gathered from the main PlantVillage dataset on Kaggle, and preprocessing was performed to suit the model. Feature extraction and classification were carried out. Provide experimental results, evaluate the VGG-16 model, and report accuracy, loss, and training time on both Google Colab and the big data environment
Introduction
Collecting data on the cultivation environment, crop growth, and yield is essential for researching and developing applications that help address difficult problems in detecting diseases on plant leaves. Analyzing and fully utilizing this massive amount of data remains a significant challenge for the agricultural industry. Therefore, studying and implementing advanced deep learning models to process and analyze big data in agriculture is extremely urgent. This requires a big data processing technology platform such as Hadoop or Spark to efficiently store and process large volumes of data. Consequently, deep learning research based on big data is an inevitable trend and crucial for building effective AI systems. Thus, this topic will provide an opportunity to enhance skills, accumulate practical experience, and gain diverse skills that are vital for future work.
In this work, we will present the proposed implementation methods based on library packages such as BigDL, BigDL Orca, TensorFlow, etc., for the development and training of deep learning models. We will introduce the proposed methodology, provide an overview of the model proposal, introduce the models, deploy them in both local and distributed environments, build a training program with support from the library packages, and train the models on Apache Spark.
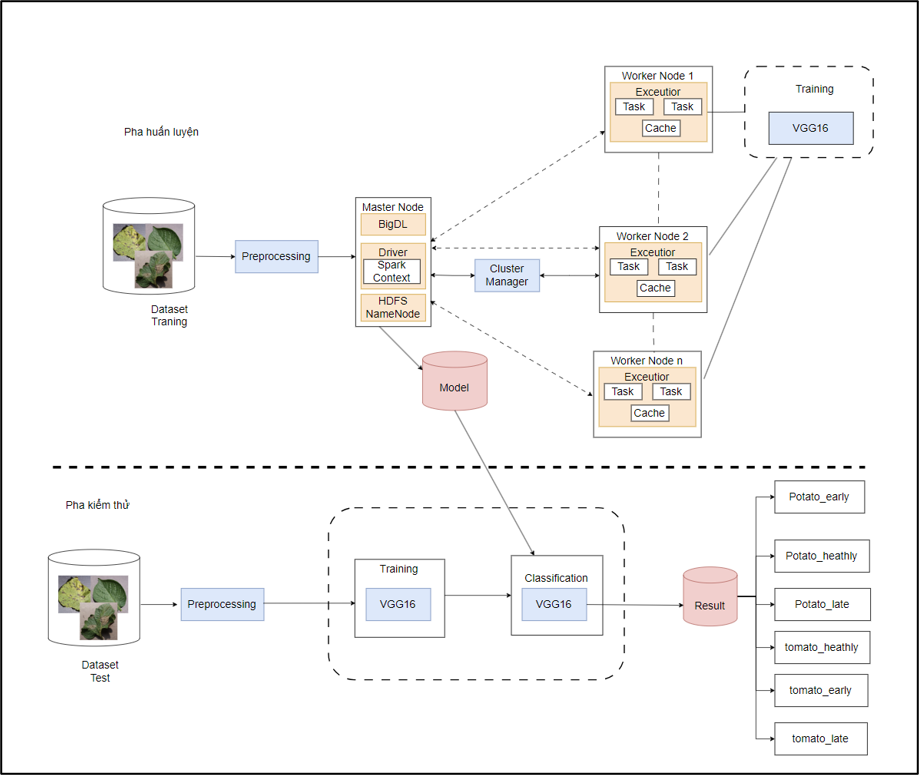
The proposed model architecture consists of 2 phases:
- Training Phase:
+ Dataset: Collect and prepare input data for the training process, create and manage datasets, handle different formats, and split into training sets as follows: train, validation, and test.
+ Preprocessing: Data preprocessing.
+ Feature Extraction: After data normalization, use the VGG16 deep learning network to extract features for training the model on disease characteristics in leaves.
+ Model: Save the trained model.
- Testing Phase:
+ Dataset: Prepare the validation dataset.Preprocessing: Data preprocessing.
+ Feature Extraction: Extract features using the VGG16 deep learning model.
+ Classification: Use the model trained in the training phase to predict classification results, evaluate accuracy, and loss on the dataset.
+ Result: Present the test results of the training process.
Proposed Method
Our proposed model includes 2 models as follows:
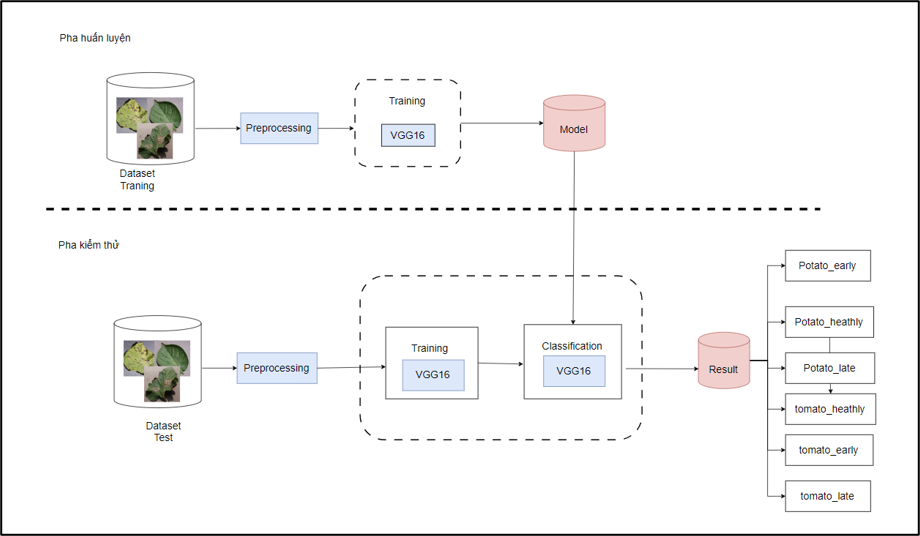
To deploy the VGG16 model in the Google Colab environment, start by initializing a Colab notebook, mounting Google Drive to access data, importing necessary libraries such as TensorFlow and Keras, and then building and compiling the VGG16 model using the Keras API. Retrieve the data from Google Drive, split it into training and validation sets, and preprocess the data to fit the model’s input requirements. Train the VGG16 model on Colab with appropriate parameters: learning rate, number of epochs, batch size, etc. Finally, classify images through the layers and provide results based on the trained model.
To deploy the VGG16 model in a big data environment, first build and preprocess the training dataset. Then, use Apache Spark's distributed technology and HDFS for processing and training the model. In the big data environment, install BigDL library packages, Anaconda, and create a Conda virtual environment. Build the VGG16 model architecture using libraries such as TensorFlow, PyTorch, etc., on Apache Spark. Partition the data into smaller chunks, create RDDs in Spark, and broadcast the VGG16 model to the worker nodes. Train the model on each data partition, compute loss, and update gradients locally. After each epoch, aggregate gradients and update the weights of the VGG16 model. This process is repeated until the loss converges and the model achieves optimal accuracy on the training set. Once training is complete, the model is saved for use in the prediction process.
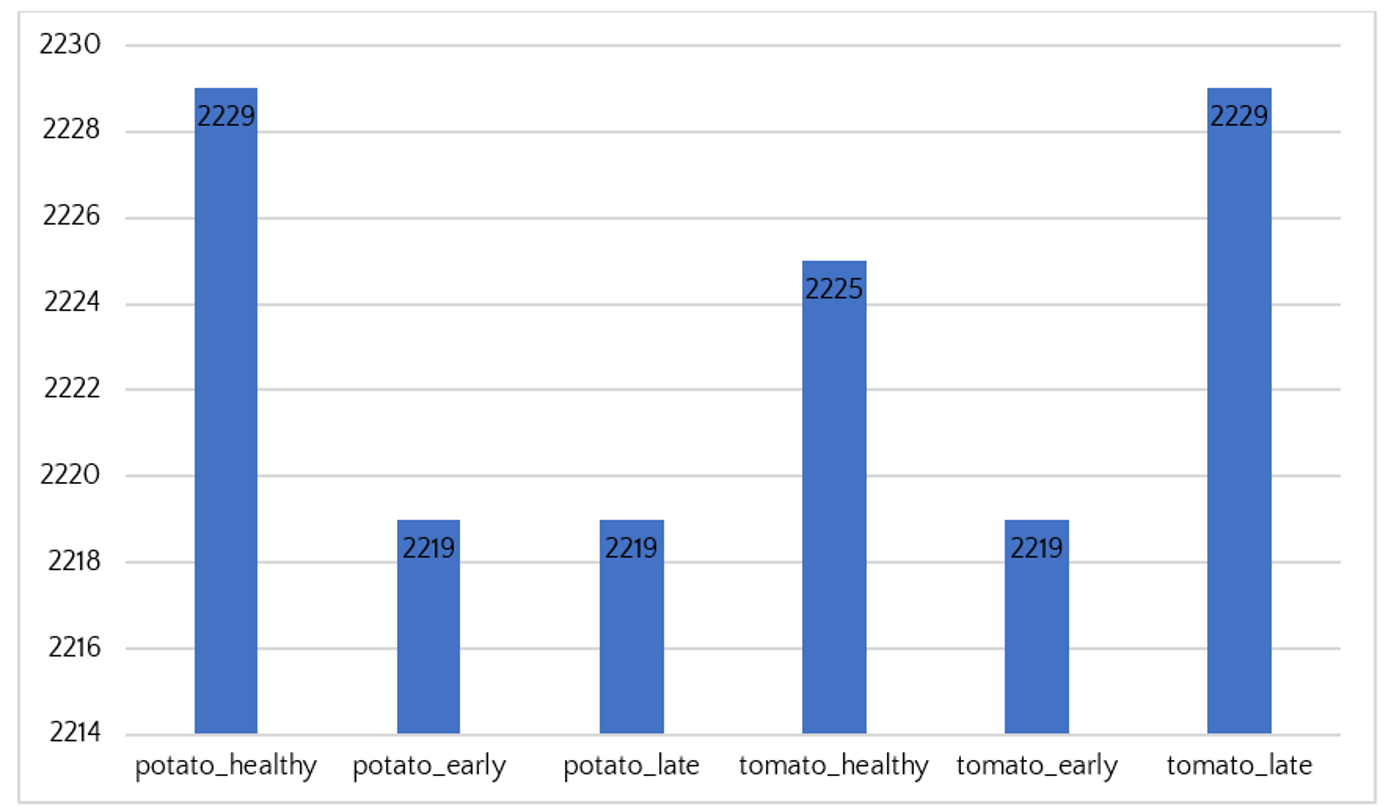
Our proposed method is tested on the dataset for classifying diseases on tomato and potato leaves mentioned above, which is part of the PlantVillage dataset and was published by Professor David Hughes' research group at the University of Pennsylvania, USA. According to the description, PlantVillage is a large image dataset of plant diseases, consisting of approximately 87,000 images with 38 different disease classes. The images in PlantVillage were collected from real-world growing conditions of plant diseases. This dataset is valuable for various research and applications related to image-based analysis, detection, and prediction of plant diseases. Additionally, the PlantVillage dataset is freely available for research purposes. From this dataset, a subset was extracted and compiled for classifying health conditions (healthy and diseased) on potato and tomato leaves, including approximately 12,000 images with training and testing datasets featuring 6 classes: healthy potato leaves (potato_healthy), early blight potato leaves (potato_early), late blight potato leaves (potato_late), healthy tomato leaves (tomato_healthy), early blight tomato leaves (tomato_early), and late blight tomato leaves (tomato_late). With a moderate number of classes (6 labels), balanced data across classes, high resolution, and accurate labels, this dataset is suitable for building and training advanced image classification models to detect and differentiate common diseases on the leaves of these two economically important crops.
Training the Model in a Local Environment (Google Colab)
- Step 1: Data Preparation: Crop and preprocess the data.
- Step 2: Model Training: The data is fed into the computation process, and during each training step (epoch), training metrics such as Loss and Accuracy are displayed
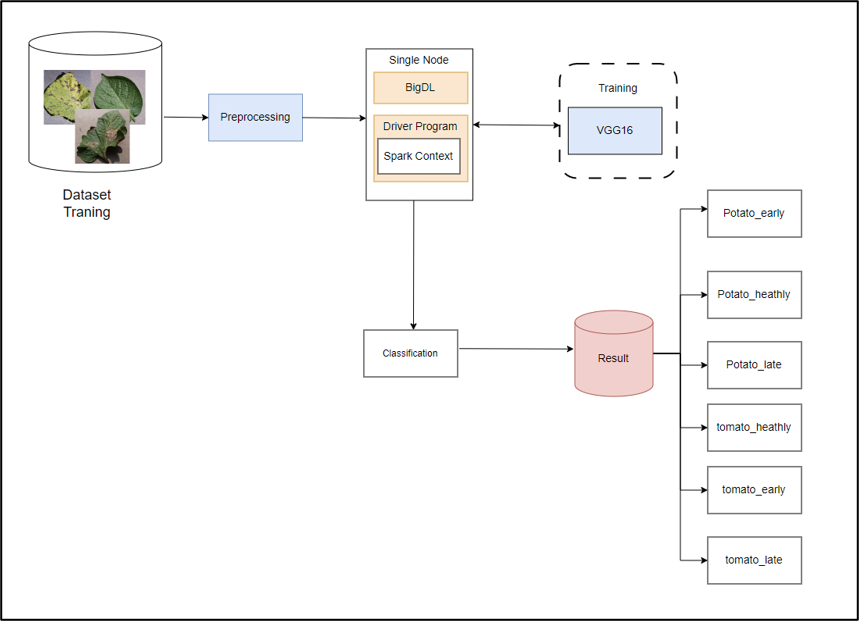
Training the Model in a Spark Single-node Distributed Environment:
- Step 1: Data Preparation: Crop, rotate, and adjust images to a consistent size, and preprocess the data.
- Step 2: Utilize tools to support and build the distributed data architecture and install the necessary library packages.
- Step 3: Train the Deep Learning Model.
- Step 4: Deploy the Model.
- Step 5: Results of the Training Process
After completing the training process, the next phase will involve deploying the trained model for classification.
Results
Local Environment (Google Colab):
Accuracy: During training, the accuracy for the leaf disease classification model (for tomato and potato plants) was as follows: After 15 epochs, the model achieved an accuracy of 97% on the training dataset and 89% on the validation dataset.
Loss: For the VGG16 model, the loss values were as follows: After 15 epochs, the model achieved a loss of 0.1% on the training dataset and 0.2% on the validation dataset.

Distributed Environment (Spark Single-node):
Accuracy: During training, the accuracy for the leaf disease classification model (for tomato and potato plants) was as follows: After 15 epochs, the model achieved an accuracy of 97% on the training dataset and 89% on the validation dataset.
Loss: For the VGG16 model, after 15 epochs, the loss was 0.1% on the training dataset and 0.2% on the validation dataset

Conclusions
Through the experiments conducted in this study, several contributions have been made:Data Collection: Assembled a dataset on leaf diseases from the main PlantVillage dataset sourced from Kaggle and performed image preprocessing to fit the model.Feature Extraction and Classification: Implemented feature extraction networks and classification methods.Experimental Results: Provided experimental results, including an evaluation of the VGG-16 model, accuracy, loss, and training time in both the Google Colab environment and large-scale data environments.
Future Directions: Utilize various network architectures to compare and select the best model, train hyperparameters to optimize performance. Employ parallel training and computation of models in a distributed data environment using Apache Spark, specifically with the Spark Multi-node model, to improve model training time. Experiment with advanced techniques such as Deep Reinforcement Learning, Autoencoder Neural Networks, and Transfer Learning to enhance the model’s predictive capabilities.
References
- Cong-Hoan NGUYEN (2015), Overview of Big Data, https://vienthongke.vn/wpcontent/up-loads/2021/04/Bai4.So5_.2016.pdf, 10/10/2023.
- Hoa THANH (2020), Learn more about Hadoop, https://viblo.asia/p/hoc-them-kien-thuc-ve-hadoop-Ljy5VqeMlra.
- . Jose´ Marı´a Cavanillas, Edward Curry and Wolfgang Wahlster (2015), New Horizons for aData-Driven Economy.
- Paul Zikopoulos, Chris Eaton and IBM (2021), Understanding Big Data Analytics for Enterprise Class Hadoop and Streaming Data , McGraw-Hill Osborne Media.
- P.L. Viana và J.B. Jones (2021),Early Blight of Tomato and Potato, United States Department of Agriculture (USDA).
- trannguyenhan, 2021, Spark, https://demanejar.github.io/categories/spark/, 1/12/2023.
- T. J. Perumanoor, About VGG16.