Abstract
In recent years, the rapid development of the World Wide Web (WWW) and the challenges in finding desired information have made effective information retrieval systems more important than ever, and search engines have become an essential tool for everyone. Information ranking is an indispensable component of every search engine, responsible for the integration of processed queries and indexed documents. Additionally, ranking is a crucial element for many other information retrieval applications, such as online advertising systems, entertainment network infrastructures, and digital content applications. Using machine learning models with the Visual Rank algorithm in the ranking process leads to the creation of more innovative and effective ranking models. Furthermore, applying Deep Learning techniques in content extraction contributes to enhancing the efficiency of information retrieval. Experimental results show that this method achieves high reliability and is very promising for research on learning to rank.
Introduction
The content of an image is perceived visually [1], and images can be either two-dimensional or three-dimensional. Therefore, recognizing content in images and converting it into characters are the prevalent recognition methods used for image search today. With the rapid development of the digital age, the volume of image data has grown, demanding significant time for computation, processing, storage, and search, and requiring complex computing systems. Input processing tasks such as normalization, character clarification, character extraction from images, and indexing are always time-consuming and present ongoing challenges for query systems. Moreover, these systems must achieve an acceptable level of reliability. However, traditional methods currently face the challenge of depending on feature extraction and recognition time. Consequently, an image retrieval method proposed in this thesis is based on deep learning methods combined with ranking techniques to improve processing times in response to practical needs. Recently, deep neural networks (DNNs) have achieved remarkable performance in various domains such as image classification, object detection, and semantic segmentation. Applying Deep Neural Network models will help diversify image content detection methods and demonstrate the effectiveness of these models compared to other architectural groups. Therefore, the research aims to select, train, and compare different Deep Neural Network architectures concerning tasks in object recognition and ranking in image data.
Proposed Method
In this study, a generalized model is proposed consisting of three stages: (1) preprocessing to create input data for the deep learning model, (2) feature extraction, (3) training, classification, and ranking. Content-based image retrieval (CBIR) involves analyzing the actual content of images for search purposes. The image content here is represented by color, shape, texture, local features, etc., or any information derived from the actual content of the image. Therefore, this study proposes a multi-phase model for extracting, classifying, storing, and ranking images, including the stages of data preprocessing, feature extraction, and ranking. The overview of the proposed model is described in Figure 1.
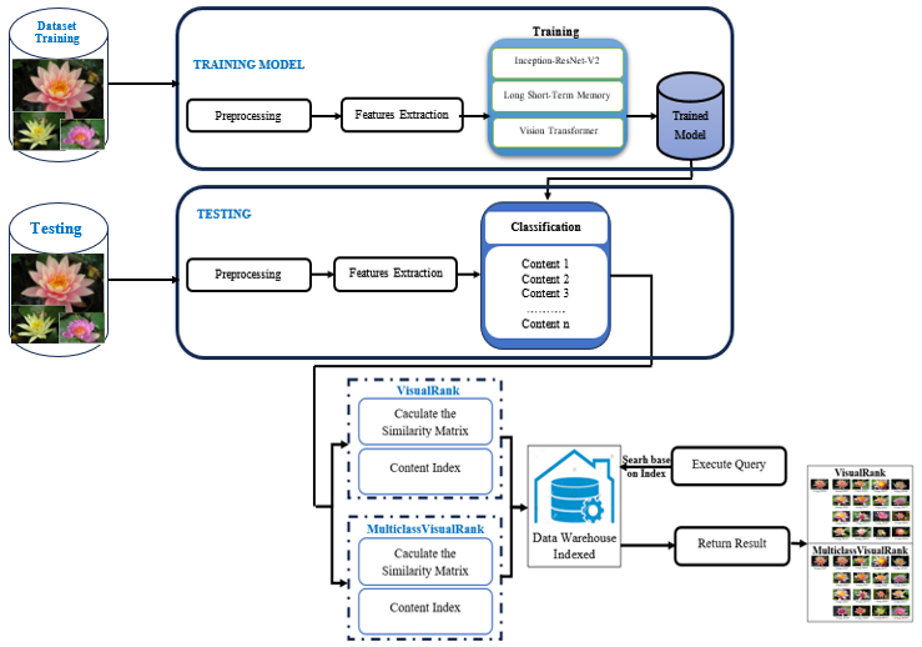
- Image Preprocessing: The input of the system is a set of available image data, where all images are normalized to a size of 224 x 224 pixels, which is suitable for the subsequent feature extraction process.
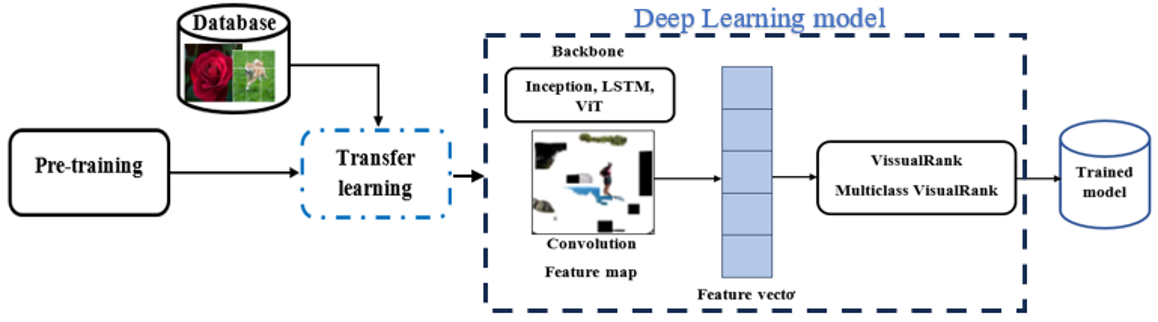
- Feature extraction and classification: This study uses transfer learning from models pre-trained on the ImageNet dataset. The pre-extracted weights from these trained models are used to continue training with the Oxford 102 Flower (102 Category Flower Dataset). Transfer learning addresses the difficulties associated with small image datasets, speeds up the learning of new features, significantly shortens training time, and saves computational resources and costs. This phase is illustrated in Figure 2.
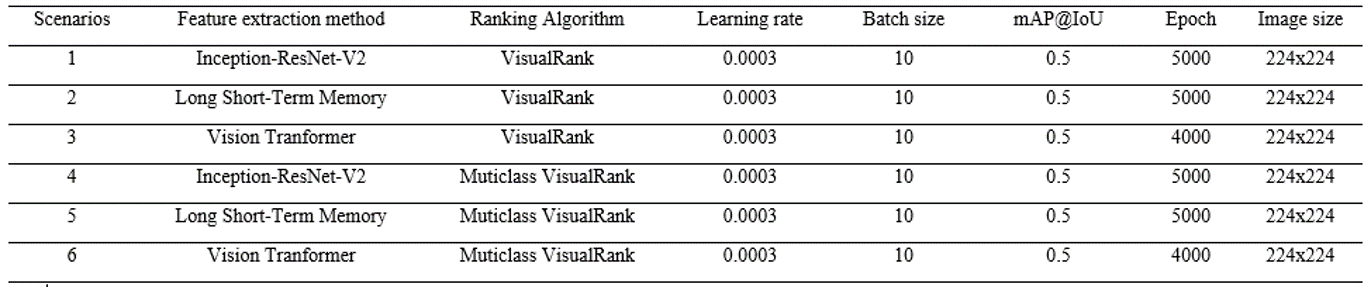
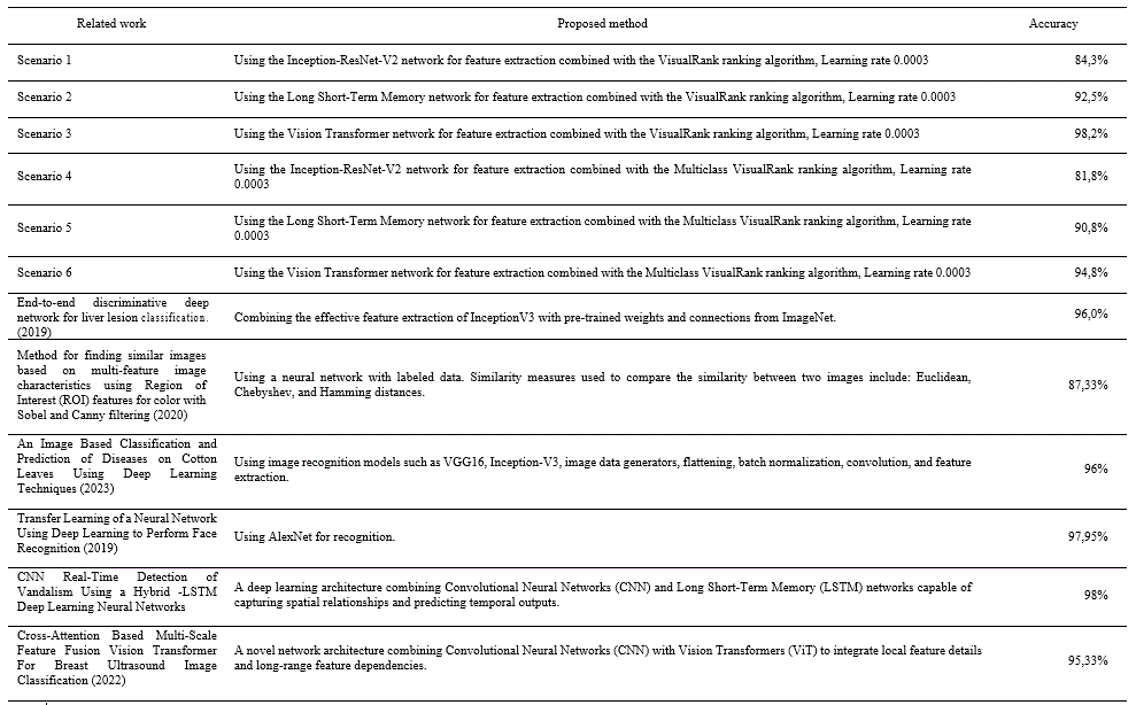
Numerous relevant documents and recent research studies were reviewed to select the experimental scenarios for the proposed model. The chosen scenarios involve well-evaluated ranking algorithms such as Visual Rank and Multiclass Visual Rank, combined with effective feature extraction networks like Inception-ResNet-V2, Long Short-Term Memory (LSTM), and Vision Transformer. This study experiments with 6 proposed scenarios along with the training parameters outlined in Table 1.
Results
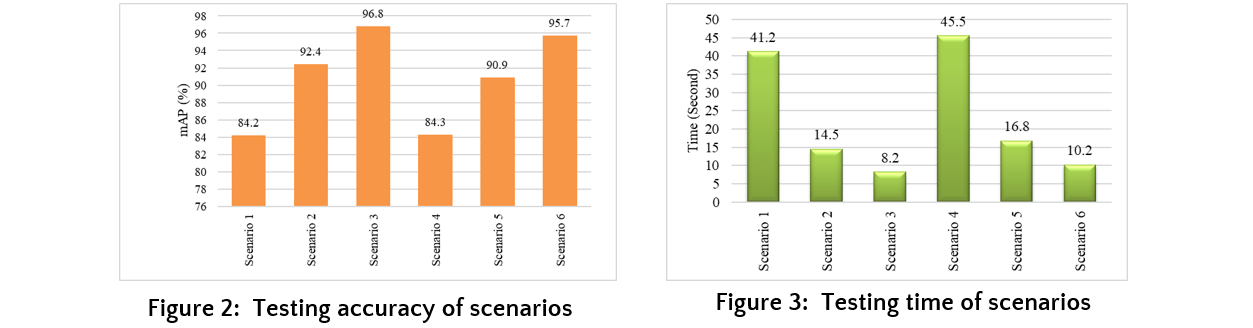
The testing process was carried out on the Test dataset consisting of 819 flower images. Figure 3 shows the mAP results from the testing on the Test dataset. The Test images were processed through the model, and the average processing time for each proposed scenario is presented in the chart in Figure 4.
The dataset was used to train the models experimentally. After training is complete, a test image of any flower type is used for evaluation. The image is processed through the classification model, which automatically selects the result with the highest accuracy as the output. Some experimental results from the scenarios are shown in Figure 4.

According to Table 2, the most notable study is by Thomas Nyajowi et al., titled CNN Real-Time Detection of Vandalism Using Hybrid-LSTM Deep Learning Neural Networks' (Thomas Nyajowi et al. 2021), which achieved an accuracy of up to 98%. This study also proposed 6 scenarios and employed deep learning models combined with ranking algorithms to enhance search performance and accommodate multiple users. The results show that most proposed scenarios achieved high classification accuracy. Among them, Scenario 3, which uses the Vision Transformer network combined with the Visual Rank ranking algorithm, achieved a high accuracy of 97.4%.
Conclusions
The study proposed six scenarios and achieved several notable accomplishments. It explored the theoretical foundations of machine learning, deep learning, Inception models, LSTM networks, Vision Transformer (ViT) models, Visual Rank and Multiclass Visual Rank algorithms, and the ElasticSearch tool. An image database was compiled for research, and models were implemented and tested, including a tool for image retrieval using a ranking-based method with image features. The study proposed scenarios using Inception-ResNet-V2, LSTM, and Vision Transformer combined with Visual Rank algorithms, identifying the best models for feature extraction, classification, and ranking. The proposed image retrieval system showed high accuracy and comprehensive results, contributing to future research. Comparative analysis with recent studies indicated that the Vision Transformer model with the Visual Rank algorithm achieved the highest accuracy, with an average mAP of 97.4%. These findings suggest that developing Scenario 3 with Vision Transformer and VisualRank for practical applications is a promising choice.
References
- Chris Baldick (2008). The Oxford Dictionary of Literary Terms. Oxford University Press. tr. 165–. ISBN 978-0-19-920827-2
- Yushi Jing(2008). PageRank for images products search. Reafered Track: Richmedia, April 21-25, 2008. Beijing, China
- Similarity Website: http://www.searchenginejournal.com/7-similarity-based-image-searchengines/8265/
- Madhavi D., & Patnaik M. R. - Genetic algorithm-based optimized Gabor filters for content-based image retrieval, In Intelligent Communication Control and Devices - Springer Singapore (2018) 157-164.
- Al-Jubouri H. A. - Integration colour and texture features for content-based image retrieval, International Journal of Modern Education & Computer Science 12 (2) (2020)
- Raja R., Kumar S., Mahmood M. R. - Color object detection based image retrieval using ROI segmentation with multi-feature method, Wireless Personal Communications 112 (1) (2020) 169-192