Abstract
Along with the strong development of the digital age, video data needs to be stored is also getting larger, requiring complex computing systems to process. In addition, today's multimedia channels are also facing challenges in terms of video query time and in-depth searches for user content. Therefore, in this paper, we have proposed a content-based video query system that takes a big data approach. In order to extract the content characteristics of the video from subtitles, images, and voices for indexing for query work, we combine optical character recognition techniques, automatic speech recognition techniques, and image object recognition techniques using DeepLearning, specifically an improved network model based on the Faster R-CNN Inception network model Resnet v2. At the same time, the proposed method is implemented in a Spark distributed and parallel processing environment to improve processing time, meeting real-time big data processing systems. This research was experimented by us on a video set of Vinh Long Radio and Television (THVL). The results show that this method has the highest accuracy of 96%, the processing time is shortened by more than 50%, and can be extended to video studies.
Introduction
Currently, video is one of the most accessible methods of information delivery for a global audience. With its advantages of being visual and dynamic, videos encompass a wide range of content without needing to explicitly convey information through language. Leveraging this content for storage and retrieval poses a significant challenge for multimedia channel managers. At Vinh Long Radio and Television Station (THVL), hundreds of gigabytes of data are stored daily, consisting primarily of videos with diverse content and formats. It is crucial to ensure accurate and quick retrieval of these videos to support professional operations. Currently, storage and retrieval are still done using traditional manual methods, which are time-consuming and prone to errors. In the near future, THVL plans to exploit previously broadcasted content. A distinctive feature of television videos is that key information such as titles, author names, and notes are often displayed as subtitles to create a lasting impression and facilitate recall among a broad audience. Extracting this information as data would make video search more accessible and accurate. Therefore, building a content-based video query system using a big data approach is essential at this time.
Proposed Method
The content-based video search system that I propose has 4 steps, as shown in Figure 1.
Pre-processing step: The main task of this stage is to improve the quality of the input video, then segment the video into subtitles, images, and voice objects.
Content extraction: I extracted the text content from the voice (1) in the audio segment, the subtitle (2), and the object (3) on the image. All the features obtained will be converted to text form. The result of this stage is a text file that corresponds to the content of the extracted video.
Content indexing step: Document indexing is the work of organizing documents to quickly respond to users' requests to search for information. The resulting index system is a list of keywords, specifying which keywords appear in which video and at which address.
Query step: To search for information that the user enters in the keyword (text) to be searched, the system will find the corresponding keyword with which video appears, and the result returned to the user is a list of videos containing that keyword (contained in subtitles, images, or voices) and ranked based on the algorithm used by the search engine.
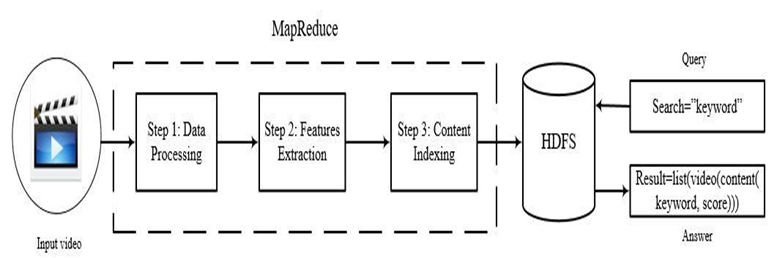
In particular, I focus on implementing and presenting in detail the stages of pre-processing, content extraction, content indexing and saving to the HDFS database. These stages are processed in parallel with the MapReduce model in the Spark environment. The details of the work are shown in Figure 2
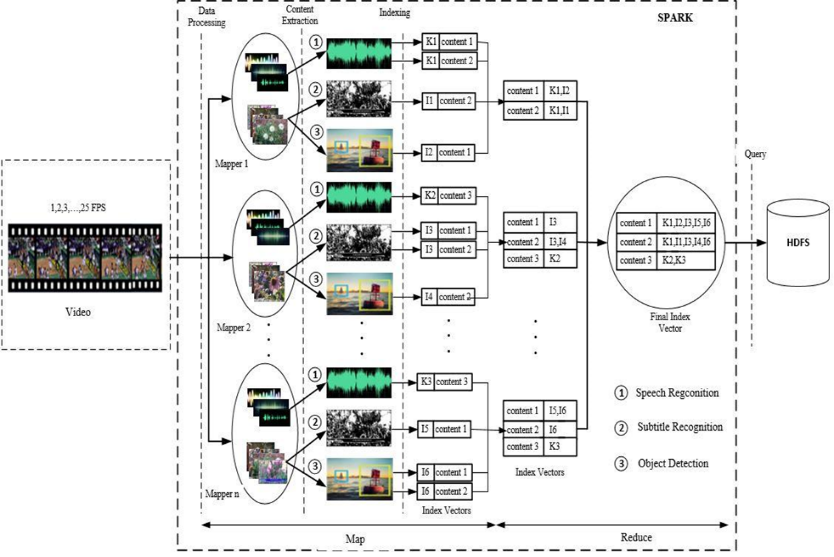
Results
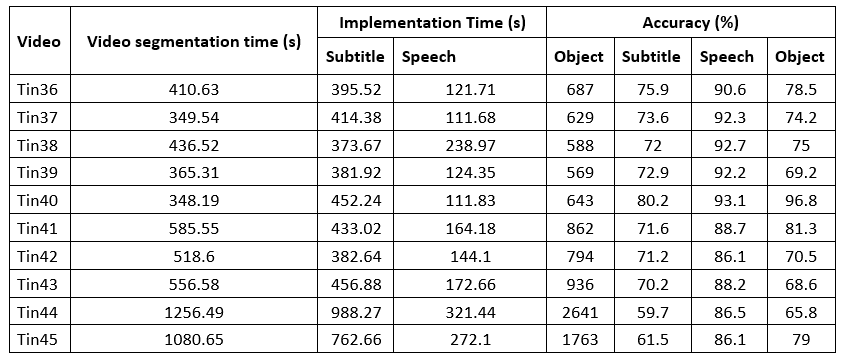
Table 1 presents the experimental results on 10 videos. I used Tesseract OCR for subtitle recognition, Speech Recognition for voice recognition, and a Faster R-CNN ResNet model in Scenario 4 for training and object recognition. The experiment was conducted in a Spark environment with the support of a MapReduce mechanism using 4 nodes. The results show that for the video named "Tin36," the video segmentation took 410.63 seconds, subtitle recognition took 395.52 seconds with an accuracy of 75.9%, voice recognition took 121.71 seconds with an accuracy of 90.6%, and object recognition took 687 seconds with an accuracy of 78.5%. Similar patterns were observed for the following videos. It can be noted that voice recognition generally had faster processing times (three times faster than subtitle recognition and five times faster than object recognition) and higher accuracy compared to the other two methods. This can be easily explained because audio processing is relatively simpler compared to image processing.
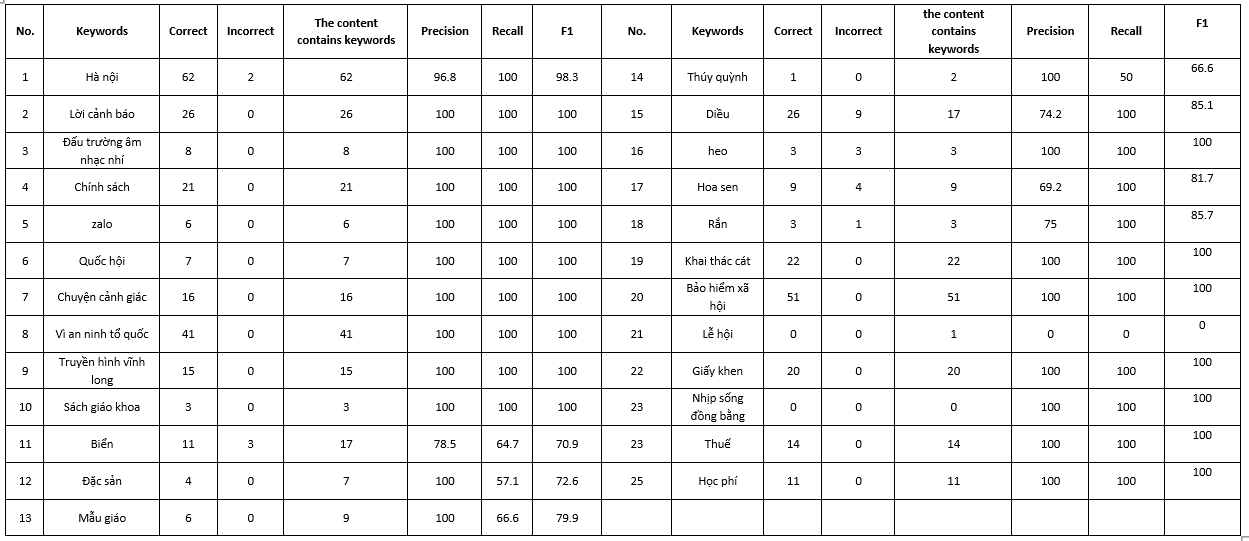
Based on Table 2, we can see that the search system returns quite accurate results for keywords referring to specific objects, such as warnings, national security, social insurance, etc. However, for more abstract keywords like specialties, kindergarten, sand mining, etc., the labeling and training process requires careful selection. Notably, the shorter the keyword, the more accurate the results returned, due to the simplicity of processing the BM25 algorithm. However, search keywords should be distinct and specific rather than common or auxiliary words.
Conclusions
The content-based video query system I proposed, which uses a big data approach, has demonstrated fairly good accuracy and returned quite comprehensive results. The content extraction method of the system combines text extraction from images using OCR techniques, speech extraction using ASR techniques, and content extraction using Deep Learning. This method also provides scientific reasoning, contributing additional evidence for selecting techniques for future research. This is the main contribution of my thesis. With the development of Deep Learning, more and more new deep learning models are emerging. Applying these models in training, subtitle recognition, and audio recognition, along with incorporating various algorithms such as noise reduction, removal of redundant characters, and filtering out stop words, are the future directions for this study.
References
- Haojin Yang. Lecture Video Indexing and Analysis Using Video OCR Technology. Proceedings of the 7th International Conference IEEE Dijon France, pp. 111-116, 2011.
- Mr. Pradeep Chivadshetti, Mr. Kishor Sadafale, Mrs. Kalpana Thakare. Content Based Video Retrieval Using Integrated Feature Extraction and Personalization of Results. International Journal of Engineering Research and Development, Volume 11, pp. 72-80, 2015.
- Min Chen, Shiwen Mao, Yunhao Liu. Big Data: A Survey. Springer Science+Business Media New York, 2014.
- Chistopher Manning, Prabhakar Raghavan, Hinrich Schutze. Introduction to Information Retrieval. Cambridge University, 2009.
- Braveen M. Content based video retrieval with orthogonal polynomials. Anna University, 2018
- Anjali Parihar, Priyanka Nagarkar, Vishakha Bhosale, Ketan Desale. Survey on Multiple Objects Tracking in Video Analytics. International Journal of Computer Applications (0975 – 8887), Volume 181 – No. 35, 2019